Standards for the Evaluation of Science Communication – International Perspectives

How can we evaluate science communication in a way that is both meaningful and fair—and should evaluation even be standardised at all? These questions remain highly contested. While some argue for a “gold standard” to ensure comparability and rigor, others caution against one-size-fits-all approaches that risk ignoring inequalities in resources, political contexts, and local needs. An international panel convened by the Impact Unit brought together diverse voices from Europe and Asia.
article by Simon Esser
Why Evaluation and Standardisation Matter
Science communication is expanding worldwide as science increasingly takes on a central role in addressing societal challenges. With this growth comes the urgent need to ensure that communication efforts are not only of high quality but also have tangible impact. Evaluation has therefore become a key theme in the field, yet there is still little consensus on what meaningful evaluation should look like.
To explore this question, the Impact Unit in Germany carried out a multi-stage consultation with practitioners, evaluation experts, researchers, funders, and leaders of science communication institutions. One particularly sensitive issue that emerged was the question of standardisation: Can and should the evaluation of science communication be standardized at all? Who should define such standards? And what should happen if evaluations fall short of them? These unresolved questions provided the backdrop for convening an international panel to broaden the perspective and bring in diverse voices from across Europe and Asia.
The event was opened by Wiebke Hoffmann from the Stifterverband, who congratulated Wissenschaft im Dialog on its 25th anniversary. She recalled the founding vision—that science should not remain in an ivory tower but engage in dialogue with society—and emphasized that this idea is more relevant than ever. Hoffmann described evaluation as a “compass” for science communication, allowing us to distinguish between mere activities and real impact. She pointed to its growing political recognition, for example in the #FactoryWisskomm initiative, and underlined that collaboration and strong alliances will be key to the future of science communication.
Building on this welcome, Liliann Fischer from Wissenschaft im Dialog set the stage for the discussion. Drawing on insights from the Impact Unit’s consultation process, she showed how the topic of standardisation had emerged as a central concern. Some experts envisioned a rigorous “gold standard” to serve as an aspirational benchmark, while others argued for a flexible, modular approach adapted to different contexts and resources. Motivations for standardisation also differed—practitioners sought comparability, researchers wanted robust datasets, and funders looked for clear criteria. Fischer stressed that these debates are far from settled, which makes international perspectives all the more important.
Standards and Inequalities
One of the first contributions came from Kenneth Fung of Universiti Malaya, who drew attention to the issue of unequal resources. His perspective set the tone for the discussion by highlighting the challenges of applying standards in diverse contexts. He stressed the stark inequalities between urban and rural settings in terms of delivery capacity and resources. Any attempt at creating standards, he argued, must take into account these disparities if it is to stand the test of time and remain adaptable to diverse local realities.
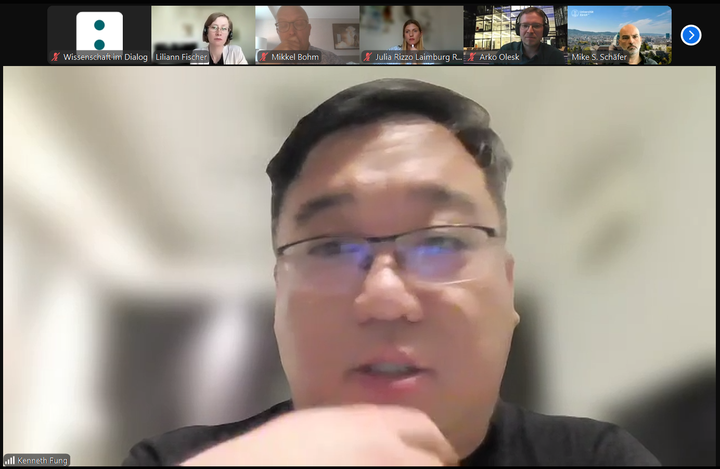
Fung also reflected on his experiences across the Asia-Pacific region. He noted that in China, and more broadly in countries such as Japan, South Korea and parts of Southeast Asia, science communication is largely shaped by the concept of science popularization. Communication efforts often serve to advance national agendas in science and technology—promoting flagship projects such as space programs or fostering high-tech industries. A central goal is to increase the number of students in STEM disciplines, thereby strengthening human capital for future development.
Fung described this approach as “very deficit model driven” and emphasized that introducing more transformative frameworks, such as a theory of change, requires a learning process. For him, this is precisely why the international conversation on evaluation and standardisation is so important: to help shift science communication from a primarily top-down, deficit-based model toward a more impact- and change-oriented paradigm.
Acknowledging Limits and Everyday Relevance
Mike Schäfer of the University of Zurich shifted the focus to the question of realism and transparency in evaluation. He emphasized that “having a gold standard does not mean not acknowledging limitations, lack of resources, or lack of support by funders.” In his view, evaluation must be realistic and allow for transparency about shortcomings as well as achievements. “Tell me what your goals are, tell me what you would like to achieve, tell me what your target group is,” Schäfer said, stressing that evaluation should provide a sense of whether objectives were met while also being able to demonstrate when things go wrong. Failure, he noted, is part of the process and should not be hidden: “We do have ****-up nights for a reason because things do go wrong and evaluations if they're done properly have to be able to show that.”
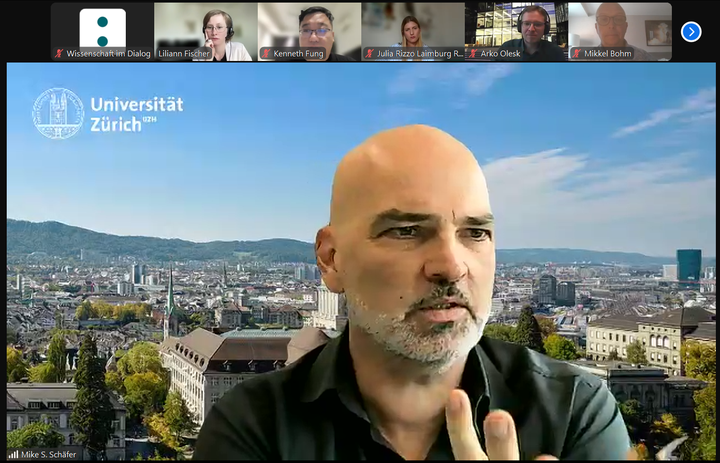
Schäfer also reminded the audience that evaluation should not be limited to a sender’s perspective. When people encounter “science” in their daily lives, it is often not in the form of grand discoveries like gravitational waves or even large-scale issues such as climate change. Instead, it may be the protein drink after a workout. “Is this really working? Can I drink a glass of wine? How does my FITBIT actually work? Should I send my three-year-old daughter to school? It's everyday life problems that they deal with and that science actually has something to say about.” Schäfer cautioned that science communication projects too often overlook these audiences, focusing instead on those already strongly engaged with science. For evaluation to be meaningful, he argued, these publics must also be considered; otherwise, evaluations risk being conducted “for the choir,” reinforcing existing affinities without reaching those who could most benefit from science communication.
Guidelines and Flexibility
From a practitioner’s perspective, Julia Rizzo of the Laimburg Research Centre in Italy highlighted the challenges of evaluating ongoing activities compared to time-limited projects. She argued that clear guidelines and “golden rules” could help to establish an evaluation culture, but that these should be flexible. She likened evaluation standards to advice for parenthood: “because parents they need advice and recommendations about how to raise kids but then they take them and raise them with their own ideas. So this is uh pretty much what we feel as practitioners”. In the same spirit, science communication projects require orientation but also the freedom to adapt. For her, standards should offer both small- and large-scale options, low- and high-effort approaches, giving practitioners a comprehensive set of tools with which to navigate the “jungle of standardisation.”
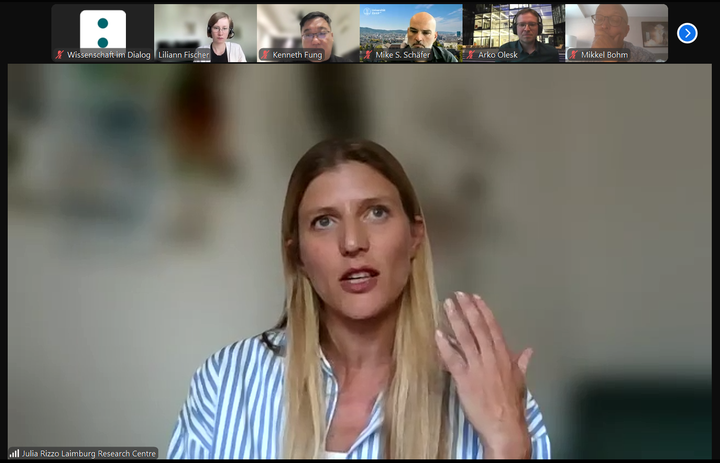
Rizzo illustrated her points with concrete examples from her own work. At the Laimburg Research Centre, evaluation takes place on multiple levels. Social media monitoring helps the team assess sentiment and engagement—whether a topic sparks dialogue or polarizes opinions. After events, they ask participants a single, simple question such as “What was most useful for you today?” This low-threshold approach, she explained, provides valuable insights without burdening audiences with long questionnaires. The most significant instrument, however, is an image survey conducted among the wider population to measure awareness and perceptions of the institution, its brand, and its activities. Until now, this survey has been carried out every five years, but Rizzo reported that the centre is moving towards a two-year cycle.
Politics, Semantics, and Power Imbalances
Arko Olesk from Tallinn University brought in the political dimension of science communication. He pointed out that the goals and definitions of “good” communication are often shaped by societal needs and political debates. Evaluation therefore cannot be separated from these broader aims. Moreover, he warned against equating audience approval with societal value: not everything that people find engaging is necessarily beneficial for themselves or for society at large.
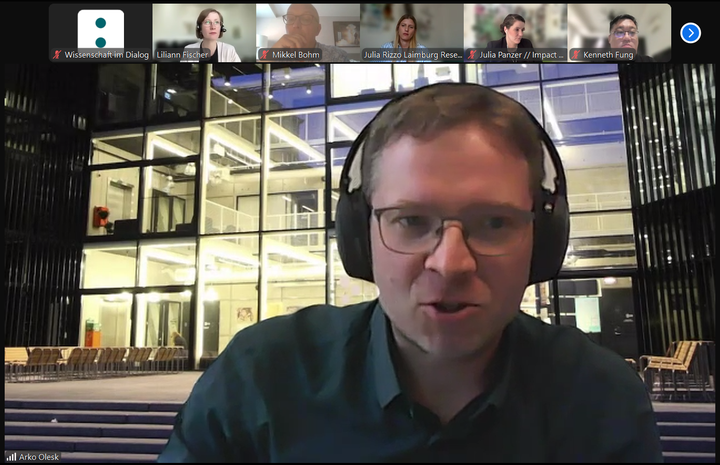
Olesk also cautioned against the language used in the debate. Terms such as “quality,” “standards,” or “enforcement,” he argued, can create resistance within the science communication community, which often sees itself as a creative field rather than one that can easily be boxed into rigid categories. What most practitioners ultimately seek, he suggested, is clarity on whether their work has meaning—and evaluation can provide tools to assess this. Yet, semantics matter: some of the vocabulary surrounding standardisation may be more alienating than helpful. Olesk further warned of a potential imbalance of power if standards were enforced too strictly. There is a risk, he said, that large institutions such as funders or universities could end up defining evaluation criteria in ways that marginalize smaller projects or independent practitioners, leaving them outside the framework. This tension, he emphasized, should not be overlooked.
Beyond Metrics: Towards Transparency
Mikkel Bohm, Director of Astra in Denmark, expressed concern that too rigid a standard could result in something “very mechanical, very primitive,” reducing evaluation to empty figures. Instead, he advocated for approaches that foster openness, dialogue, and transparency. Drawing on experiences from Denmark, he noted that some funders already create spaces where grantees can meet, exchange experiences, and speak honestly about their failures. For him, standards should be less about rigid procedures and more about creating a shared culture of values and trust.
Bohm also highlighted the central role of impact in funding processes. When researchers or practitioners apply for grants, he noted, they typically promise change: to engage more local citizens in city planning, to inform communities around a laboratory, or to raise awareness in specific groups: “Impact is your selling point when you make an application”. Yet, while it is relatively easy to count website hits or event participants, it is much harder to demonstrate whether such efforts have truly led to change. Bohm explained that in his experience reviewing international funding proposals, applicants often describe outputs but fail to show how they intend to measure outcomes and impact. This gap, he argued, requires more critical attention from funders. Standards—or at least clearer expectations—could help, provided they remain open to dialogue and allow projects to acknowledge when they achieve results different from those initially planned. In his view, such openness would strengthen evaluation cultures and move discussions beyond simplistic metrics.
Conclusion: Living Standards, Not Rigid Rules
Across these contributions, one conclusion emerged clearly: evaluation is indispensable, but a one-size-fits-all approach to standardisation is unlikely to succeed. Instead, the future lies in developing living standards—flexible frameworks rooted in shared values, openness, and adaptability. These should provide orientation and foster a culture of reflection without stifling diversity or innovation.
The event demonstrated that evaluation in science communication must be both principled and pragmatic, attentive to context and inequality, and open to acknowledging not only successes but also failures. In short, standards should not close the conversation—they should create the conditions for ongoing dialogue.
You can watch the recording of the lunchtime talk on our YouTube channel.
Practical tips and sources of inspiration for your evaluation can be found on the Impact Unit website.